近日,档案智能开发与服务国家档案局重点实验室,武汉大学计算机学院李祖超副研究员团队在ACM International Conference on Multimedia(ACM MM) 发表题为“Enhancing Visually-Rich Document Understanding via Layout Structure Modeling”的文档理解研究领域最新研究成果。ACM MM 是国际多媒体领域学术和产业界交流的最顶级盛会,也是中国计算机学会推荐的多媒体领域唯一的A类国际学术会议。
近年来,使用多模态预训练的Transformer已经在视觉丰富的文档理解方面取得了重大进展。然而,现有的模型主要关注文本和视觉等特征,忽略了文本节点之间布局关系的重要性。本文中,我们提出了一种新颖的文档理解模型GraphLayoutLM,它利用布局结构图建模来将文档布局知识注入到模型中。GraphLayoutLM利用图重排算法来调整基于图结构的文本序列。此外,我们的模型使用布局感知的多头自注意力层来学习文档布局知识。该模型能够理解文本元素的空间排列,提高文档理解能力。
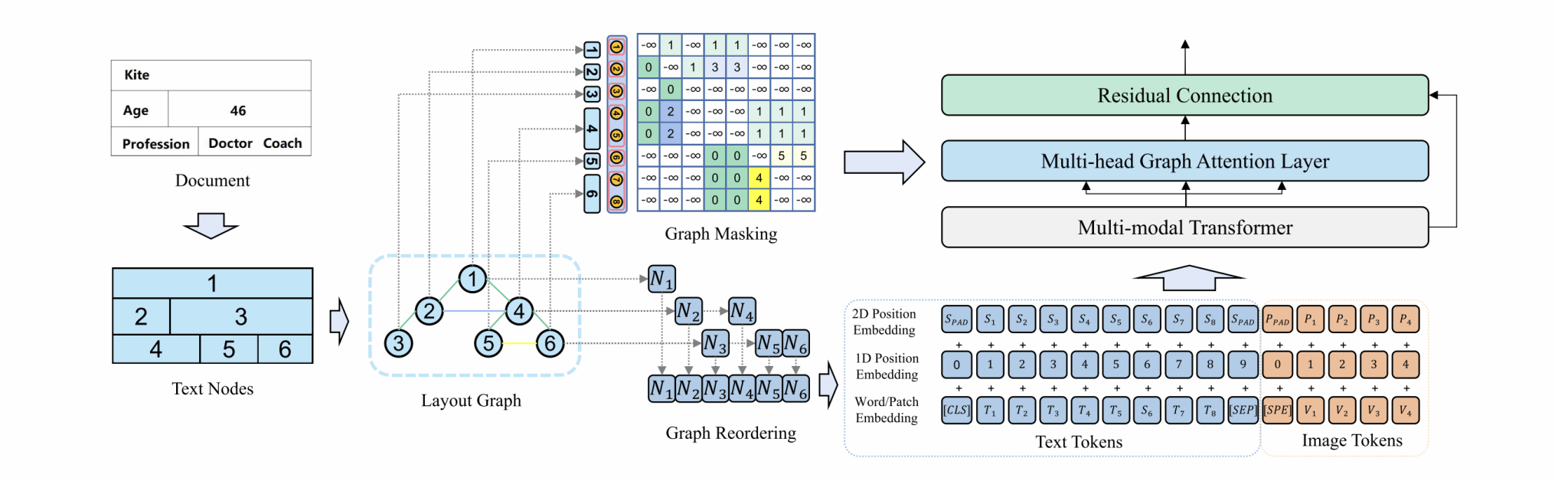
图1 GraphLayoutLM架构
我们在包括FUNSD、XFUND和CORD在内的多个基准数据集上评估了我们的模型,并在这些数据集中取得了最先进的结果。实验结果表明,我们提出的方法明显改善了现有方法,并展示了将布局信息纳入文档理解模型的重要性。我们还进行了消融实验,以研究我们模型的每个组成部分的贡献。结果表明,图重排序算法和布局感知的多头自注意力层在实现最佳性能方面起着至关重要的作用。

图2 FUNSD和CORD测试集的结果
该研究获得了国家自然科学基金、湖北省自然科学基金、中央高校基金等项目的资助。

